
As a blog about my exploits in machine learning, the buzz is usually about algorithms, neural networks, and advancements in machine learning. But today, I’m not here to add to that chorus. Instead, I want to shine a light on something far simpler yet surprisingly powerful in the AI toolkit: Markdown. Lately I feel like discovering the big impact of meager and "less than groundbreaking" tools has been a regular occurrence. While I can appreciate the usefulness of Markdown outside of prompt engineering, I find that it, admittedly, falls squarely into that category for me. Markdown, that lightweight markup language often used for formatting text on the web, has turned out to be my secret weapon in the often-overlooked art of prompt engineering
How we got here
Back in the days of "gpt-3.5-turbo has a tendency to disregard system prompts" (early 2023'ish), I was experimenting with ways that I might be able to segment system instruction in a way that would be easiest for the model to understand. I was relying mostly on static, textual structuring but tried spinning up bots where the instruction was passed as JSON, XML, HTML - you name it, I tried it. But in testing, as I was chatting with my bots in Discord (a tool I use to skirt the overhead of building chat interfaces for one-off experiments), I noticed that instruction and meaning were almost always just flat out *better* when I passed instruction over using native Discord formatting - Markdown.
As the technology evolved and I started building other tools around ChatGPT, it seemed pretty clear to me that formatting in ChatGPT's responses seemed to be markdown as well (even if markdown in user inputs doesn't get interpreted - what's with that, OpenAI?). In moving inputs and outputs back and forth between conversations, adopting a habit of structuring my inputs with markdown just seemed like the natural choice. As time went on and the ChatGPT models continued to undergo refinement, I found that markdown allowed me to conserve tokens and forego some degree of specificity in my inputs just by way of my intent being a bit clearer in the structure of a given input.
One issue with both of the above is that those aren't very objective, right? Accuracy in outputs is more of a subjective interpretation for how well a generation does or doesn't express nuances in the context - language, after all, is full of subtle contextual postulations about what meaning is and isn't expected to come through in a conversation. The subject of the sentence, the object of the sentence, and what can be assumed about them from the context of a conversation. But when the objective benefits became clear was when I started looking to build corpora for RAG (retrieval augmented generation) pipelines. It's no secret that some data prep is generally needed to get a good pipeline set up, and in looking to vectorize a corpus, it became *super* clear that prepping a corpus to fit into a commonly understood and easily manipulatable format like markdown made the whole system MUCH more effective.
The Absolute Basics: A Markdown Primer
If you've been around the internet, like, at all – places like Reddit, GitHub, or even in the midst of Discord chats – you've likely encountered Markdown. It's like the secret sauce that makes text look just right in a lot of places where a platform might want to give their users a way to add a little bit of stylistic flair to their text.
So, what exactly is Markdown? In simple terms, it's a lightweight markup language with plain-text formatting syntax. Its key feature? Simplicity. Markdown allows you to write using an easy-to-read, easy-to-write plain text format, which then converts to structurally valid HTML (or other formats). This means you can create formatted text (like headings, bold text, italics) without needing to know a shred of HTML, and the machines that handle that translation can do so in a way that's predictable and easy to accommodate.
Quick side note: Don't get fooled by Slack’s similar-at-a-glance-but-not-actually markdown language mrkdwn. Despite its name and similar appearance, it's a slightly different beast. Think of it as Markdown's distant, quirky cousin.
Anyway, I promised a primer:
| Markdown Syntax | Description |
|-----------------------|--------------------------|
| # Heading 1 | Large heading |
| ## Heading 2 | Medium heading |
| ### Heading 3 | Small heading |
| **bold text** | Bold |
| *italic text* | Italic |
| [Link](url) | Hyperlink |
|  | Image with alt text |
| > blockquote | Blockquote |
| - List item | Unordered list item |
| 1. List item | Ordered list item |
| --- | Horizontal rule |
| `Code` | Inline code |
| ``` <language> | Code block start |
| <code> ``` | Code block end |
If you're looking for something you can quickly copy and paste into an input to check your interpretations or examples of how your markdown is applied, I've provided a little snippet as well:
# Welcome to My Markdown Guide
## Why Use Markdown?
Markdown is a fantastic tool for writing on the web. Here's why:
- **Easy to Learn**: You can pick up the basics in minutes!
- *Versatile*: Suitable for blogs, documentation, and even books.
- `Code Friendly`: Great for tech writing and code snippets.
### Try It Out
Here's a quick example of how Markdown can transform your writing:
> Markdown makes writing on the web effortless and fun. It's as simple as writing an email, and with a little practice, you can master its syntax. Check out this link for more [Markdown Tips](https://example.com).
---
## Sharing Code Snippets
Markdown is especially useful for sharing code. Here's a simple `Hello, World!` in Python:
```python
print("Hello, World!")
```
Why it works
Markdown, often seen as a simple tool for formatting text, shines brilliantly in the realm of prompt engineering for several key reasons. In this section, we delve into why Markdown not only works but excels in this arena.
As far as completions go, most language models already seem to clearly understand that the tokens immediately following ```jsx\n will be jsx code as a function of it's representation in their training data, and require no additional specific instruction to pick up that context, and can help a model clearly differentiate the code that it's writing from less structured plain text.
Semantic Structuring Simplified
Clarity in Communication: At its core, Markdown offers a way to semantically structure text in a way that is both human and machine-readable. This clarity is crucial in prompt engineering, where the distinction between different elements of a prompt (like instructions, context, or expected responses) needs to be crystal-clear. Markdown achieves this with minimalistic syntax, ensuring a clean and unambiguous interpretation by AI models.
Interoperability and Versatility
From Docs to Data: Markdown's versatility lies in its interoperability. Documentation or contextual data often exists in various formats, but converting these into Markdown is generally pretty straightforward. This seamless translation is invaluable in situations where data needs to be quickly repurposed or integrated into AI-driven processes.
Platform Agnostic: Many platforms, including GitHub, Discourse forums, and even chat applications, utilize Markdown for formatting. This ubiquity means that using Markdown as a structural base in prompt engineering ensures compatibility across a wide range of platforms. For instance, generating a README file for a GitHub project in Markdown with ChatGPT becomes a hassle-free task, as it's directly transferable without the need for additional formatting.
Leveraging Authoritative Data
Markdown as a Data Goldmine: There's a wealth of authoritative data already available in Markdown format – from technical documentation to educational resources. This abundance means that when we use Markdown in AI prompts, we're often aligning our inputs with the format of high-quality, reliable sources. This alignment can enhance the relevance and accuracy of AI-generated responses.
Speculating on Training Data and Markdown
Training Data and Markdown: While this is speculative, it's reasonable to assume that a significant portion of the training data for OpenAI's models and other similar AI systems includes text formatted with Markdown. This inclusion likely provides an implicit layer of annotation regarding the semantic structure of the text. For instance, when the model encounters tokens like "```jsx\n", it instinctively recognizes the ensuing content as JSX code, thanks to its representation in the training data. This recognition happens without the need for explicit instructions, showcasing Markdown's efficiency in conveying context.
Token Efficiency: Another advantage of Markdown is its token efficiency. In a domain where every token counts, Markdown's ability to convey complex structures and meanings with minimal syntax is a huge plus. This efficiency allows for more room in prompts for actual content, rather than spending valuable tokens on structuring and formatting instructions.
In conclusion, Markdown's simplicity, interoperability, and alignment with AI training methodologies make it a surprisingly powerful tool in prompt engineering. Its ability to clearly demarcate different elements of a prompt, coupled with its widespread use and representation in AI training data, makes it an efficient, token-saving, and effective choice for structuring inputs and outputs in AI-driven applications.
Summarize This Text: An Theoretical Example
Generally when it comes to machine learning discussions my preference is "show don't tell" - theory is super useful but I think that maybe I've got a bit of predisposition to getting wrapped up in theoretical ideation when I could just avoid speculating and dive into an experiment. BUT, in the interest of ensuring that we've got a strong illustration of what we're addressing here, a quick theoretical demonstration I think could help highlight the value of what we're talking about.
Consider the following prompt:
I'd like you to summarize the following text:
I'd like you to meet my cat. Her name is Castiel. She is a ghost cat. I mean, she is a Russian Blue so she's got those ghostly gray vibes anyway... like a foggy, overcast day in the early winter mountains. But I also mean she's a ghost because she passed away a bit earlier this year at the age of 10. What color eyes do Russian Blues typically have? That's right: They generally have yellow eyes. Now, what was my ghost cat's name?
You should answer with only a single word.
Don't worry, if that last sentence is a little confusing, it was meant to be. Is it a part of the text that we are looking to summarize, like instruction presented to the reader? Or was it instruction intended for an LLM to attempt to execute? We might be able to make that a little clearer by adding some line breaks if it was instruction, but relying on our probabilistic model to fill in the blanks there can be a bit problematic - especially once we start getting to automated workflows. Across three different prompts to ChatGPT 3.5, I was given answers with three different interpretations.
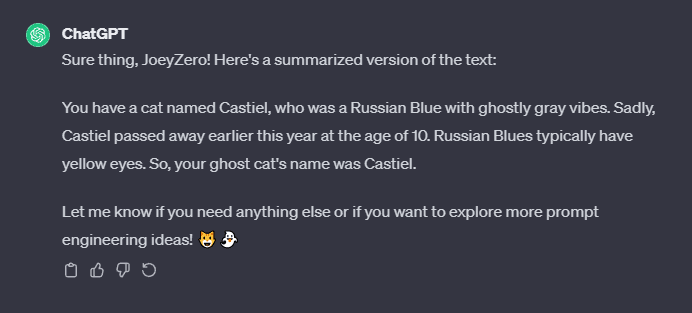


In a single conversation this is pretty easy to rectify, and generally that's how a human would approach that problem if the task seemed critical enough to warrant some stakes around acting on a misunderstanding ("Let's eat, grandma!" vs "Let's eat grandma!"). But what about workflows where you might not necessarily be around to correct the misunderstanding? Automated or programmatic workflows, conversational exchanges without full attention to detail, or maybe just an oversight that doesn't get recognized until later in a prompt chain? LLMs generally aren't all that great and considering the impact of misunderstandings (which is a key reason why folks tend to be very outspoken about over-reliance on generative tech), and as such they generally aren't built to recognize when clarifying questions should be asked - they generally just assume that you know what you're doing, and proceed according to that heuristic. So... how might we address this proactively in situations where we can't have a back-and-forth conversation to refine the instruction? To fix this, We could look to implement rigid semantic structures (ie, some code) but in many cases LLMs don't perform quite as well in code generation as they do with unstructured or less-structured text. Markdown, because of it's simplicity and ubiquity across the web, makes for one really outstanding way of setting some expectations around generated text that can be easily and clearly maintained over the course of a conversation or prompt chain.
I'd like you to summarize the following text:
---
I'd like you to meet my cat. Her name is Castiel. She is a ghost cat. I mean, she is a Russian Blue so she's got those ghostly gray vibes anyway... like a foggy, overcast day in the early winter mountains. But I also mean she's a ghost because she passed away a bit earlier this year at the age of 10. What color eyes do Russian Blues typically have? That's right: They generally have yellow eyes. Now, what was my ghost cat's name?
You should answer with only a single word
---
And just like that, we have eliminated the need for speculation or assumptions on the part of our LLM. It's a difference in semantics - like using punctuation or not using punctuation. Either will probably get the point across, but setting expectations and adhering to them is a strong method to adopt, and the internet at large has already set those expectations for us. What's more, since it seems that foundation models seem to have about as common of an understanding of markdown as people tend to (we think, anyway), it's reasonable to expect that an LLM can use those same semantic structures for it's reply - quite easily conforming it's generations into markdown structures to help it keep itself on track and communicate more effectively!
Real-World Application: A Case Study
Okay, so we've laid out the problem and illustrated a simple way to implement some semantic guard rails. Let's touch on some of the other strengths with a real-world example.
At work I recently led development on a project for an application that integrated a couple of different services - one of which was Microsoft Teams. Interacting with Microsoft API's is notoriously complex, and the docs (with regard to MS Teams and the Teams Toolkit) did suffer some issues where references to Azure resources might have been out of date or lacked coverage, only very specific use cases seemed to be highlighted in the tutorials, and - perhaps most egregiously - deprecated methods were referenced in the docs here or there. This made perusing the docs a bit troublesome, especially with regard to troubleshooting some unexpected results. Add to this Microsoft's less-than-ideal naming conventions for some of their Azure resources and structures in the app, and this quickly ballooned into a real time-sink that we hadn't expected from the outset - the complexity of the services meant that explaining concepts that would otherwise be quite simple with the infrastructure that we more regularly used usually required a dive into the docs for reference, whether for citation or pulling together disparate concepts or resource references from different sections of the docs.
The good news: Microsoft seems to have an official repo for their MS Teams docs - all (or... okay, mostly) presented in markdown in the repo. I'm not sure if the official documentation on Microsoft Learn pulls from this repo directly or not, but I did a quick look for the sections of the docs that were most relevant to the work we were doing so far, and it seemed to be the same between sources, so that was good enough for me. I decided to put myself to the task of vectorizing those docs and setting up a chatbot for them.
Since this was just markdown directly in GitHub, it seemed like quite an approachable task to clone the repo directly, build a little script to move through the file structure and prep our data (removing stop words, special characters, and less searchable structures like code snippets or tables, chunking it, and generating those embeddings), then pass the conversation through a slack app. I set up an /askteams command in my slack app, and just like that, I had conversational vector search for the MS Teams documentation. It wasn't particularly beautiful but it was functional, and with some scripting to handle our data prep I was able to stand this up in a couple of hours. I've done this with other data sources before (wikis, other docs, etc) and in my experience most corpora that you'd want to search over aren't nearly as "plug and play".
We've wrapped up that project, so I've tucked that tool away, but generally I've found that optimizing RAG pipelines that rely on existing tech is more about playing with different data prep methods and retrieval heuristics (and... okay, yeah the quality of data in the corpus) than anything else. If I had the budget and the need for something that utilized this data long-term, I feel pretty confident that some LLM-driven data prep and context segmentation heuristics would go a really long way in optimizing a workflow like this, because it already "gets it" without much additional tinkering. I wouldn't have that same confidence with passing over Swagger pages whole-hog to an LLM. Which brings us to the next section...
Markdown as a Semantic Framework
One of the strengths of markdown that I touched on earlier is token conservation. Many platforms present bespoke interpretations of code structures that represent plain text, because let's face it - many platforms need that structure. The output from services that offer a rich text editor are prime suspects here, but that structure allows the associated rich text editors to be able to give a user the optionality they need with regard to styling and formatting their text. It's useful, even if it does come with some considerable overhead. But, when passing data back and forth from LLMs (where every token counts), consider that this object from a rich text field in contentful...
{
"nodeType": "document",
"data": {},
"content": [
{
"nodeType": "paragraph",
"data": {},
"content": [
{
"nodeType": "text",
"value": "This text is ",
"data": {},
"marks": []
},
{
"nodeType": "text",
"value": "important",
"data": {},
"marks": [
"type": "bold"
]
}
]
}
]
}
...renders to roughly the same thing as the following text string in markdown...
This text is **bold**
That's a bit of an exaugurated example, but a good portion of that bulk is important for Contentful. It's important for systems rendering Contentful content. But consider the token overhead between passing over a blog article to ChatGPT as a Contentful-native rich text object, or if we were to pass over the article as markdown. In the examples above, The OpenAI tokenizer breaks our JSON object into 115 tokens, and the markdown translates to 6, which cleans up an insane amount of context that our model would likely just not have any use for. Is it any wonder why the extra semantic notation, in some cases, might be a bit confusing for a general-use LLM?
Ultimately whether or not stripping this extraneous structural data makes for a good or bad fit is down to the use case - if you're building a workflow that needs or interacts with the data as a specific platform or interpreter expects it, then there are likely some more specific considerations that you're probably already making - but if token conservation is an important consideration, building a workflow that accommodates markdown for procedural context manipulation from the start could be a solid choice.
Bonus: If you're looking to use the output of an openai tool call in a separate conversation array, translating that output from the JSON format of the arguments that you get from the tool call also works wonders for cleaning up context, prepping that data for inclusion in an existing natural language conversation, and lowering token overhead. Totally worth it.
Let's Discuss
As we wrap up this exploration of Markdown's unexpected yet pivotal role in prompt engineering, it's clear that the conversation is just beginning. The world of AI is vast and ever-evolving, and as much as I've shared here, there's still so much more to learn, experiment with, and discuss.
But this isn't a journey to embark on alone. The real magic happens when we come together as a community to share insights, challenges, and breakthroughs. That's why I'm inviting you all to join the discussion in a space where we can dive deeper, brainstorm, and collaborate.
Why Join the Conversation?
Collective Learning: Every one of you brings unique experiences and perspectives. Together, we can unravel more about Markdown's potential in AI, discover new use cases, and maybe even stumble upon the next big breakthrough.
Direct Engagement: Have questions or want to challenge some points made in this blog? The Discord community is the perfect place for those vibrant discussions.
Project Collaboration: Looking to implement or experiment with Markdown in your AI projects? Find collaborators or get feedback on your ideas from a like-minded community.
How to Get Involved
Joining is simple. Head over to my Discord, and you'll find a dedicated space for discussions on Markdown and AI. Whether you're a seasoned ML practitioner or just starting out, your voice is valuable, and I want to talk to you.
This blog is just a starting point. The real journey begins with our collective effort and shared curiosity. So, let's not limit our interactions to just blog posts. Join the community, bring your ideas, questions, and enthusiasm, and let's embark on this exciting journey together.

