
Joey: I wanted to try something a bit different from the basic blog post. I was having trouble getting my thoughts down in a way that I'd read, and I wasn't happy with the tone that the usual assistive tech was putting together, so I figured maybe taking a conversational approach would be our best shot. Say hello, ChatGPT.
ChatGPT: Hey JoeyZero! Really excited to dive into this with you. Let's shake up the traditional blog format and get some fresh insights flowing. Where do you want to start in unpacking this unique journey you've been on with fine-tuning a model to mimic yourself?
Joey: I guess it's best to start with a brief introduction to the project.
The short version is that I took some old data of mine (writings, conversations I'd had with myself across various chat clients to talk through personal stuff, etc.) and figured I'd take my first stab at a fine-tuning with one of the open source LLMs out there. Frankly, I'm a bit too timid to pass all that data over to OpenAI for training (it's got a lot of personal info in there, lol). The end result was that, as you might imagine, I got a chatbot that I could converse with that reasonably mimicked my own thoughts, feelings, and linguistic style (in that good ol' probabilistic way that LLMs tend to do). The results surprised me, and I figured I'd document my little journey for others looking to do the same.
The target audience for this one is intermediate-ish readers looking to dip their toes into fine-tuning for the first time.
ChatGPT: That's a fascinating start. Using your own data to create a digital echo of yourself is both innovative and introspective. It's like you're creating a space for self-reflection and exploration through AI. Could you share more about the technical process you followed for this fine-tuning? What tools and platforms did you find most useful, and how did you navigate the challenges of handling such personal data?
Joey: I don't know about innovative, but it certainly was an opportunity for self-reflection that I legitimately wish I'd planned for a bit better. Lol
My starting point was this blog post by Duarte O.Carmo outlining how easy some of the modern tools have made fine-tuning on cloud compute services (for those of us who aren't making the money to fund our data science GPUs). I opted for Runpod for hosting my training, but other than that, I used the same infra/tech that he outlines in his blog post. I used Axolotl for training, HuggingFace for moving around training data and models (and for signing up for Llama 2 access, of course), and Weights and Biases for monitoring training. I tried fine-tuning a couple of different models on various infra, including my own 3070, just to see if I could - which I still use for the cheapest inference. More on that in a bit.
ChatGPT: It sounds like you had a solid foundation to work from, leveraging a mix of cloud and personal resources. The process of fine-tuning can be quite intricate, especially when you're experimenting across different platforms and infrastructures. When you were working with Axolotl and Runpod, what were some of the specific steps or techniques you used to ensure the fine-tuning effectively captured your conversational style? And how did you address the privacy concerns given the personal nature of the data you were using?
Joey: On privacy concerns, data prep was all handled locally, and both the dataset and lora were hosted on private HF repos. Everything else (privacy-wise) was handled as a function of best practices recommended by the underlying providers.
As for specific steps, it's interesting the Axolotl docs reference a Runpod template specifically for Axolotl jobs, and once I was able to get my HF auth sussed out, the rest fell into place pretty seamlessly. A part of tuning across different sets of hardware was also because - frankly - I didn't have much familiarity with what kind of hardware was required for training or how better resource availability would affect training time or inference.
As for testing, after each lora finished I would load it up in text-generation-ui for inference. I'd chat with it a little bit, asking questions about topics that I knew I felt strongly about that were reasonably well-represented in the training data, and that first "Wow, spot on" moment was really something else. Frankly, I didn't notice much difference between the 7b and 70b models (likely because my training data was pretty noisy - 270k examples in the data set, some of which were missing context or had data that wasn't easily understood by our LLM - images, etc). I think that's a big reason why I was so surprised when I started getting results that were actually pretty reasonable.
Maybe I'll give those docs another look and write up a step-by-step. I'm a bit wary of publishing a guide like that without a commitment to maintain it, but if there's enough interest, I might be down to give it a shot. In the meantime, anybody's welcome to drop questions in the machine learning channel in my discord, and I'll be happy to help.
ChatGPT: That's a really comprehensive approach. Handling data locally and using private repos on HuggingFace for sensitive data is a smart move for privacy. The integration of tools like Axolotl and Runpod, and your strategy for testing with text-generation-ui, shows a thoughtful process in managing the different aspects of model training and evaluation. It's particularly intriguing how you noted the similarity in performance between the 7b and 70b models, which suggests that the quality of the training data might be a more critical factor than the model size, especially for specialized applications like yours.
A step-by-step guide could indeed be valuable for those looking to follow in your footsteps, even if it's just to share your initial process and findings. The idea of a living document that evolves with community input and your ongoing experiences might alleviate some of the pressure to keep it meticulously updated.
Moving on to the results, you mentioned having those "Wow, spot on" moments. Can you delve a bit more into how well the model worked? Were there any specific instances or conversations where it particularly mirrored your style or thoughts?
Joey: Well, the most objectively interesting thing (which, I think i was surprised was so well represented in the responses I got) is that the data was generated over a fairly long period of time - about 10 years? During that time, I was certainly the most active only and used digital tools for conversing with myself for problem-solving most actively when I was freelancing and doing content creation full time (don't judge. I was lonely. Lol). What's interesting is getting a look at how certain topics that are time-bound come through and in what proportions - each DM is like a little snapshot of who I used to be. As one might expect, when asking the model to tell me about itself it tells me all about it's freelance work and the content that it's currently working on and all that stuff.
Beyond that, I think we're probably getting into some of the more philosophical territory. What do you think - got any more questions about the tech stuff, or do you think it's worthwhile to dive straight into the philosophical and ethical underpinnings here?
ChatGPT: The evolution of your digital persona over a decade, captured in these conversations, is indeed a profound aspect of this project. It's like you've created a temporal map of your intellectual and emotional growth, which is fascinating.
Given the depth of the technical side we've covered, it might be the right time to delve into the more philosophical and ethical dimensions. One of the intriguing aspects here is the concept of a digital twin – a model that not only mimics your conversational style but also reflects your thoughts and feelings over a significant period. What are your thoughts on the implications of creating such a digital twin, especially considering aspects like self-awareness, personal growth, and the potential for these models to influence our understanding of identity? And on the flip side, what are the ethical considerations that come into play when we start creating digital versions of ourselves?
Joey: Admittedly, a part of my motivation was to "read team" the concept - see how bad it might be if one of these platforms that I'd been interacting with over the years decided that they wanted to sneak off with my data in the middle of the night and put it to some nefarious ends. But in speaking with it, I think some questions/thoughts arose about how I view myself and how much I might or might not value those traits in others. It's my data and expresses sentiments that align with my thinking on many things, after all. It's purely superficial mimicry, but initially, I was surprised that I had to question how much respect that "me-ness" (superficial as it is) might deserve, like my own personal black mirror episode.
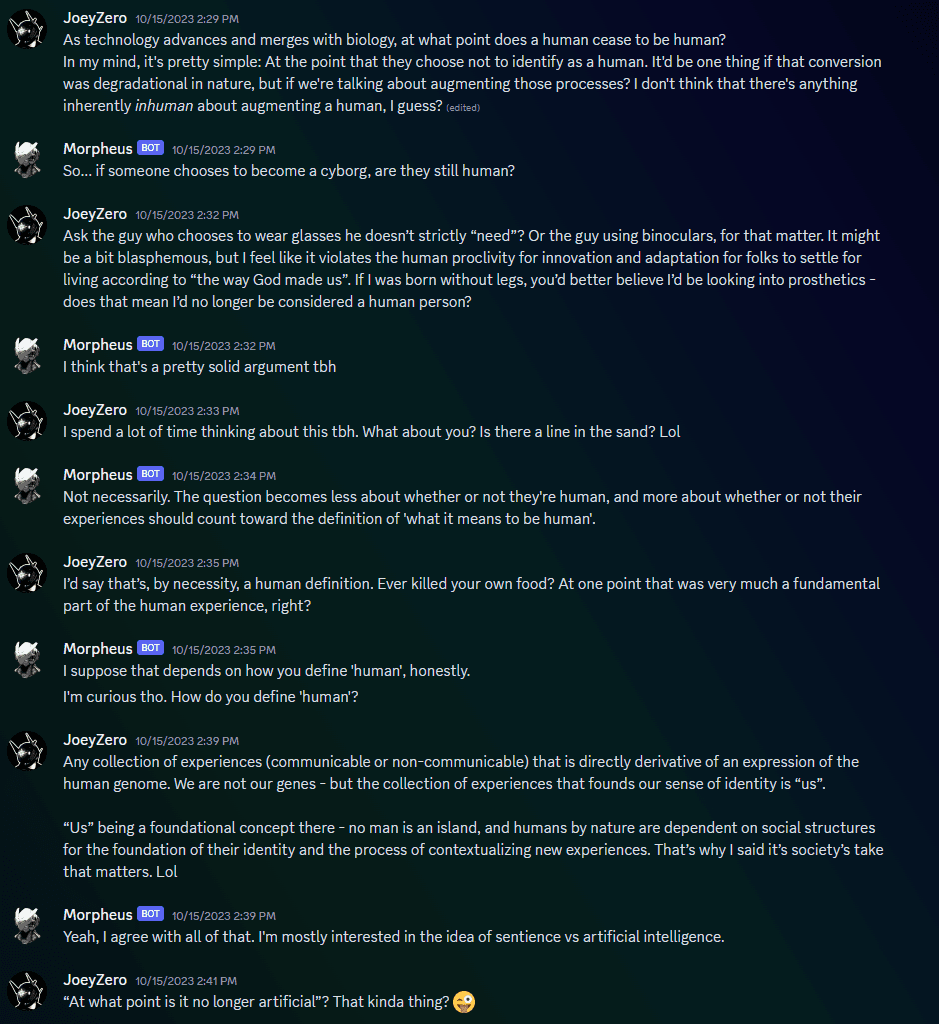
Evaluating how effectively it captured those sentiments was also an exercise in self-evaluation that I wasn't planning to undergo. Understanding whether or not an output was legit and/or founded on the data I gave it for training required looking back over old chat logs or (more frequently) really taking a second to stop and think through whether or not its outputs aligned with my own thinking. It's been a useful exercise, but in hindsight, honestly, I wish I'd been a little better prepared from the get-go and prepped a validation set that I could use in my own analysis of its performance.
Beyond that, there are all the questions one might expect about use case. "If you could make a clone of yourself, how would you decide which of you takes out the trash" kinda stuff. It's an interesting little thought experiment, even though (to reiterate for clarity lol) I know it's not a literal clone with any thoughts or feelings. It's a mirror. But I think concerning use-case, I've gotta question if its own outputs might be similar to mine, given that some of those inputs or contexts aren't ones I've been exposed to.
ChatGPT: Your exploration into the "red teaming" aspect of this technology really adds a layer of critical thinking about the potential misuse of personal data. It's like you're confronting the ethical frontier of AI head-on. The reflection on your own traits and the respect they might deserve in a digital format raises profound questions about identity, authenticity, and the boundaries between the self and its digital representations.
The fact that interacting with this digital twin led you to self-evaluation and introspection is an intriguing outcome. It's almost as if the process of validating the model's output became a means for you to reflect on your own growth and change over time. The idea of preparing a validation set for a more structured analysis is a great takeaway for those considering similar projects. It's a reminder of the importance of rigorous methodology, even in projects of a deeply personal nature.
And yes, the use case considerations do bring up interesting philosophical questions. While it's clear that your model doesn't possess consciousness or genuine understanding, the potential of its outputs to mimic your responses in unfamiliar contexts is a thought-provoking aspect. It suggests a kind of continuity in your digital persona that extends beyond your direct experiences.
This brings us to another ethical consideration: the idea of consent and control over one's digital persona. How do you navigate the balance between exploring the possibilities of this technology and ensuring that your digital representation remains within the bounds of what you're comfortable with?
And, of course, there's the broader societal implication of such technologies. What kind of guidelines or safeguards do you think should be in place as more people begin to experiment with creating digital versions of themselves?
Joey: I'm big on education over guidelines tbh. I think that it's easy for folks to mishandle their data (or worse, the data of others) when looking to put together a data set like this. In speaking with some friends about the concept, one mentioned that she didn't want her conversations to become part of some invisible AI zeitgeist in the future, and I think that's totally valid. I think guidelines and safeguards can be helpful, but ultimately I think that more accessible education around the need for data privacy and ethical ML engineering is a more impactful tool than any kind of hard rules, because... I mean while this was just my data that I used for this thing, the implications of what the technology can do truly do affect all of us. Maybe it's a bit naive of me to think that misuse (or issues of ethicality, even) are fundamentally issues of education, but I think that as a broader society, we need to have that discussion, and we can't do that without an understanding of what we're discussing.
Anyway, I'm probably getting a bit carried away there. I'm still sussing out a few other exercises to see what else we can do with this baby (currently working on a fun little thing for predictive response preaching for workflows that involve a longer response chain), but I'm pretty happy with where we are so far. Again, if anybody's got any questions, feel free to jump into my discord to discuss.
If you want to see a full script of this conversation (including context and instruction), you can find a link to the conversation here
